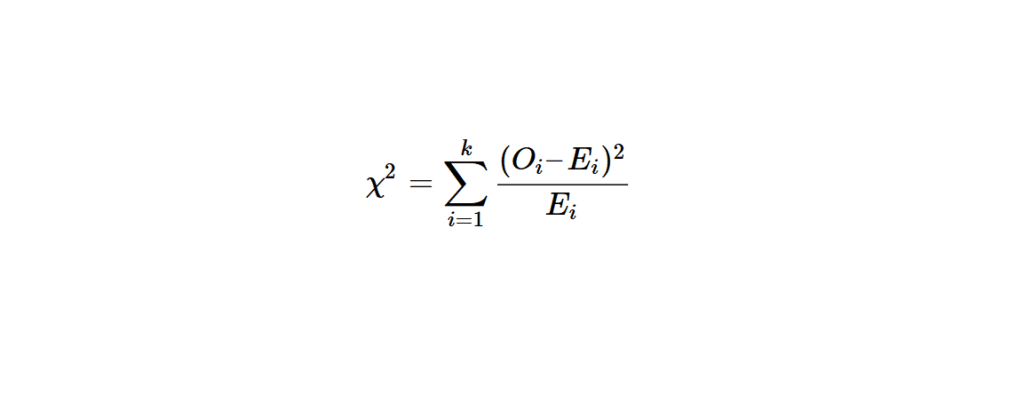
En prépa ECG, on apprend à simuler des lois de probabilité et à calculer des estimateurs. Mais une question reste souvent sans réponse : comment vérifier rigoureusement qu’un jeu de données suit bien une loi donnée ? L’œil nu ne suffit pas : un histogramme peut ressembler à une loi normale sans que ce soit statistiquement établi. C’est précisément le rôle du test du khi-deux d’adéquation, qui fournit une réponse objective et quantifiée à cette question. Bien que hors programme ECG au sens strict, il mobilise des notions entièrement au programme : loi du khi-deux, probabilités, estimateurs et intervalle de confiance. Dans cet article, nous allons présenter les fondements du test, détailler sa mise en œuvre pas à pas, puis l’implémenter en Python sur deux exemples concrets.
Fondements du test
Dans cette partie, nous effectuerons quelques rappels sur les fondements mathématiques des tests d’ajustement statistiques, mais le cœur de cet article vise son implémentation en Python.
Si tu veux en apprendre plus côté maths, voici un article.
Le cadre général
On dispose d’un échantillon de taille \(n\) et d’une loi de probabilité candidate \(P_0\). On cherche à tester si l’échantillon est compatible avec cette loi. Alors, on formule deux hypothèses :
- \(H_0\) (hypothèse nulle) : l’échantillon suit la loi \(P_0\).
- \(H_1\) (hypothèse alternative) : l’échantillon ne suit pas la loi \(P_0\).
Le test du khi-deux d’adéquation repose ainsi sur une idée simple : on découpe l’espace des valeurs en \(k\) classes, on compte le nombre d’observations dans chaque classe (effectifs observés \(O_i\)) et on compare ces effectifs à ceux que l’on attendrait si \(H_0\) était vraie (effectifs théoriques \(E_i = n \cdot p_i\), où \(p_i\) est la probabilité théorique de la classe \(i\) sous \(H_0\)). Si les effectifs observés s’écartent trop des effectifs théoriques, on rejette \(H_0\).
La statistique de test
L’écart global entre effectifs observés et théoriques est mesuré par la statistique de Pearson :
\[\chi^2 = \sum_{i=1}^{k} \frac{(O_i – E_i)^2}{E_i}\]
Cette statistique est toujours positive et vaut \(0\) si et seulement si \(O_i = E_i\) pour tout \(i\), c’est-à-dire si l’échantillon colle parfaitement à la loi théorique. Ainsi, plus elle est grande, plus l’écart entre données et loi candidate est important.
La loi de la statistique sous \(H_0\)
Sous \(H_0\), et lorsque \(n\) est suffisamment grand (règle pratique : \(E_i \geq 5\) pour tout \(i\)), la statistique \(\chi^2\) suit approximativement une loi du khi-deux à \(k – 1\) degrés de liberté, notée \(\chi^2(k-1)\). Ce résultat est admis en prépa, mais il repose sur le théorème central limite appliqué aux fréquences empiriques. D’ailleurs, cette loi de probabilité a déjà été abordée dans des sujets de Maths II !
Si des paramètres de la loi \(P_0\) ont été estimés depuis l’échantillon (par exemple, la moyenne et la variance d’une loi normale), on soustrait un degré de liberté par paramètre estimé : on obtient alors \(\chi^2(k – 1 – p)\) où \(p\) est le nombre de paramètres estimés.
Mise en œuvre du test
Les étapes à réaliser en Python
La mise en œuvre du test suit toujours le même enchaînement en cinq étapes, qu’il convient de connaître par cœur pour les concours.
- Choisir le nombre de classes \(k\) et construire les intervalles, en s’assurant que chaque effectif théorique \(E_i = np_i\) est supérieur ou égal à \(5\). Si ce n’est pas le cas, on regroupe des classes adjacentes afin de vérifier absolument cette condition.
- Calculer les effectifs observés \(O_i\) (compter les observations dans chaque classe) et les effectifs théoriques \(E_i\) (calculer \(np_i\) sous \(H_0\)).
- Calculer la statistique \(\chi^2 = \sum_{i=1}^{k} \frac{(O_i – E_i)^2}{E_i}\).
- Déterminer le seuil de rejet. Pour un niveau de signification \(\alpha\) (souvent \(5\%\)), on lit dans la table de la loi \(\chi^2(k-1)\) la valeur critique \(\chi^2_{\alpha}\) telle que \(P(\chi^2(k-1) > \chi^2_{\alpha}) = \alpha\).
- Conclure. Si \(\chi^2 > \chi^2_{\alpha}\), on rejette \(H_0\) au niveau \(\alpha\). Sinon, on ne rejette pas \(H_0\), ce qui ne signifie pas que \(H_0\) est vraie, mais seulement que les données sont compatibles avec elle.
La p-valeur
En pratique, plutôt que de comparer la statistique à une valeur critique tabulée, ce qui est moins pratique en Python, on calcule directement la p-valeur :
\[p\text{-valeur} = P(\chi^2(k-1) > \chi^2_{\text{obs}})\]
C’est la probabilité d’observer un écart au moins aussi grand que celui observé, si \(H_0\) est vraie. Une p-valeur inférieure à \(\alpha = 5\%\) conduit au rejet de \(H_0\). Plus la p-valeur est petite, plus les données sont incompatibles avec la loi candidate. En Python, pas de souci puisque scipy.stats.chisquare calcule directement la statistique et la p-valeur.
Implémentation en Python
Exemple 1 : tester l’adéquation à une loi uniforme
Dans cet exemple, on simule \(n = 600\) lancers d’un dé à six faces et on teste si le dé est équilibré, c’est-à-dire si chaque face a la même probabilité \(\frac{1}{6}\). À l’évidence, nous allons utiliser la bibliothèque numpy en Python mais, dans la réalité, il faudrait calculer à la main les lancers du dé pour obtenir les vecteurs des chiffres tombés lors des lancers.
Après exécution de ce script, on obtiendra un résultat sous la forme :

- Statistique χ² = 1.60
- P-valeur = 0.9012
- Décision : Non-rejet de H0
On obtient donc une P-valeur très largement supérieure à 5 %, donc rien ne permet d’exclure \(P_0\). Autrement dit, rien ne permet d’exclure que les lancers suivent une loi uniforme (c’est rassurant, les dés étaient équilibrés par définition de la fonction ‘random’ !).
Analyse du script
On dispose de \(k = 6\) classes et aucun paramètre estimé, donc la loi de la statistique sous \(H_0\) est \(\chi^2(5)\). On compare les effectifs observés (proches de \(100\) chacun, puisque le dé est simulé équilibré) aux effectifs théoriques \(E_i = 100\). La statistique sera faible et la p-valeur élevée : on ne rejette pas \(H_0\), ce qui est cohérent.
Exemple 2 : tester l’adéquation à une loi normale
Ici, on génère un échantillon de taille \(n = 500\) depuis une loi \(\mathcal{N}(0, 1)\) et on teste si cet échantillon suit bien une loi normale, dont on estime la moyenne \(\mu\) et l’écart-type \(\sigma\) depuis les données. On découpe l’espace en \(k = 8\) intervalles de probabilité égale \(\frac{1}{8}\) sous la loi normale estimée.
Analyse
Attention à bien comprendre les deux lignes compliquées de ce script.
À la ligne 10, on construit les (k+1) bornes des classes. norm.ppf(i/k, mu, sigma) calcule le quantile d’ordre \(\frac{i}{k}\) de la loi \(\mathcal{N}(\mu, \sigma^2)\)estimée. En choisissant des quantiles régulièrement espacés, on garantit que chaque classe a la même probabilité théorique \(\frac{1}{k}\) sous \(H_0\), ce qui simplifie le calcul des effectifs théoriques. On ajoute \(-\infty\) et \(+\infty\) aux extrémités pour que la première et la dernière classe soient non bornées.
À la ligne 11, on calcule les effectifs observés. Pour chaque classe (i), (echantillon >= bornes[i] & (echantillon < bornes[i+1]) est un tableau de booléens qui vaut True pour chaque observation tombant dans la classe (i), et np.sum compte justement le nombre de True. La compréhension de liste répète cette opération pour les (k) classes.
Attention, cependant ! Puisque l’on a estimé \(2\) paramètres (\(\mu\) et \(\sigma\)) depuis l’échantillon, le nombre de degrés de liberté est \(k – 1 – 2 = 5\) et non \(k – 1 = 7\). Ne pas soustraire les paramètres estimés est une erreur classique qui conduit à sous-estimer la p-valeur et à rejeter \(H_0\) trop souvent. Ici l’échantillon ayant été généré selon une loi normale, la p-valeur sera élevée et on ne rejette pas \(H_0\).
Conclusion
En conclusion, le test du khi-deux d’adéquation est un outil statistique rigoureux et polyvalent, applicable à n’importe quelle loi discrète ou continue dès lors que l’on sait calculer les probabilités théoriques des classes. Il s’appuie sur des notions au programme (loi du khi-deux, estimateurs, p-valeur) et son implémentation Python tient en quelques lignes grâce à scipy.stats.
Maîtriser les cinq étapes de sa mise en œuvre et savoir corriger les degrés de liberté quand des paramètres sont estimés sont deux points de méthode directement évaluables en concours.
Il n’y a plus qu’à croiser les doigts pour qu’un tel thème tombe aux concours !
Tu peux retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux également accéder ici à toutes nos autres ressources mathématiques !