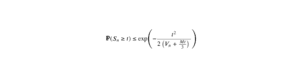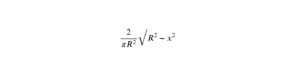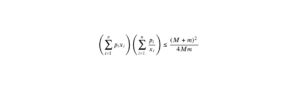Que tu sois en première ou en deuxième année de prépa, maîtriser ton cours sur les probabilités est essentiel. Major-prépa te propose donc une fiche récapitulative sur les espaces probabilisés et les techniques à connaitre pour bien réussir ses concours. Prêt ? C’est parti !
Quand peut-on parler de mesure de probabilité ?
La notion de Tribu est désormais hors programme depuis 2021.
La notion de probabilité
Soit \( (\Omega , \mathcal{A} ) \) un espace probabilisable.
On peut véritablement parler de probabilité que si dans un espace probabilisable on trouve \(P \) une loi de probabilité qui vérifie les trois propriétés suivantes :
- \( P \) est une application de \( \mathcal{A} \) dans \( [0,1] \).
- \( P(\Omega) = 1 \).
- \( P \) est \( \sigma\)-additive, c’est-à-dire que pour toute famille finie ou dénombrable d’éléments disjoints \( (A_i)_{i \in I} \in \mathcal{A}^{I} \) : \( P\left(\displaystyle \bigcup_{i \in I} A_i \right) = \displaystyle \sum_{i \in I} P(A_i)\). \( \\ \) En particulier, \( P(\emptyset) = 0 \).
Enfaite, on peut tout simplement remarquer que la mesure de probabilité est un cas particulier de mesure … Les plus matheux d’entre-vous découvriront cela en école !
Le triplet \( (\Omega , \mathcal{A}, P ) \) est appelé espace probabilisé ou espace de probabilité.
La \( \sigma \)-additivité nous permet de déduire la sous-additivité : Pour toute famille finie ou dénombrable d’éléments \( (A_i)_{i \in I} \in \mathcal{A}^{I} \) telle que \( \displaystyle \sum_{n=0}^{+ \infty} P(A_n) \) converge, on a : \( P( \cup_{n=0}^{+ \infty} A_n) \le \displaystyle \sum_{n=0}^{+ \infty} P(A_n) \).
La Notion d’évènement
Après avoir défini le cadre propice aux mesures de probabilité on peut parler des événements :
Tout d’abord, on définit \( \Omega \) “l’univers”, comme étant l’ensemble des issues pouvant être obtenues au cours d’une expérience aléatoire.
Quelques propriétés à connaître :
-
Complémentarité :
\( \forall A \in P(\Omega )\) , \( P(A) = 1 – P(\bar A) \).
-
Probabilité conditionnelle :
Soient \( A, B \in P( \Omega) \) deux évènements tels que \( P(B) > 0 \). On appelle probabilité conditionnelle de A sachant B, la probabilité : \( P(A|B)=P_B(A)=\frac{P(A\cap B)}{P(B)} \).
-
Formule des probabilités composées :
Soient \( A_1, …, A_n \) des évènements tels que \( P(A_1 \cup … \cup A_{n-1}) \ne 0 \). On a : \( P(A_1 \cup … \cup A_n) = P(A_1)P_{A_1}(A_2)P_{A_1 \cup A_2}(A_3)…P_{A_1 \cup … \cup A_{n-1}}(A_n) \).
-
Formule des probabilités totales :
Soit \( A_1, …, A_n \) un système complet d’évènements tel que : \( \forall i \in [\![1,n]\!], P(A_i) \ne 0 \). Soit \( B \) un évènement.
On a : \( P(B) = \displaystyle \sum _{i=1}^{n} P(A_i)P_{A_i}(B) \)
-
Formule de Bayes :
Soit \( A_1, …, A_n \) un système complet d’évènements tel que : \( \forall i \in [\![1,n]\!], P(A_i) \ne 0 \). Soit \( B \) un évènement.
\( \forall j \in [\![1,n]\!] \), on a : \( P_{B}(A_j) = \displaystyle \frac{P_{A_j}(B)P(A_j)}{\displaystyle \sum _{i=1}^{n} P(A_i)P_{A_i}(B)} \).
-
Formule du crible :
\( \forall A, B \in P(\Omega ) \) , \( P(A \cup B)\) = \( P(A) \) + \( P(B) \) – \( P(A \cup B) \)
On peut alors en déduire par récurrence la formule du crible de Poincaré généralisée (hors programme ECG):
\( \forall (A_i)_{i \in I} \in \mathcal{A}^{I}, I \subset [\![1,n]\!]\) , \( P( A_1 \cup … \cup A_n ) = \displaystyle \sum_{k=1}^{n} (-1)^{k+1} \sum _{1 \le i_1 < … < i_k \le n} P(A_{i_1} \cap … \cap A_{i_k}) \).
-
Limites monotones :
\( \forall (A_i)_{i \in I} \in \mathcal{A}^{I} \) suite croissante d’évènements i.e \( A_1 \subset A_2 \subset … \subset A_n \subset … \), on a : \( \displaystyle P(\cup_{n \in \mathbb{N}} A_n) = \lim \limits_{n \to +\infty} P(A_n) \).
\( \forall (A_i)_{i \in I} \in \mathcal{A}^{I} \) suite décroissante d’évènements, on a : \( \displaystyle P(\cap_{n \in \mathbb{N}} A_n) = \lim \limits_{n \to +\infty} P(A_n) \).
Variables aléatoires discrètes
Soit \( (\Omega , \mathcal{A}, P ) \) un espace probabilisé et \( E \) un ensemble.
On dit que \( X : \Omega \to E \) est une variable aléatoire discrète si, \(X(\Omega ) \) est fini ou dénombrable et, pour tout \( x \in E \), \( X^{-1}\)({\( x \)}) \( \in \mathcal{A} \). \( X \) est une variable aléatoire discrète réelle si \( E = \mathbb{R} \).
Loi de probabilité
On appelle loi de probabilité de \(X\) la suite des \( P(X=x_n) \) avec \( X(\Omega) =\) {\( x_n ; n \in I\)} et \( I \) fini ou dénombrable.
Indépendance de deux variables aléatoires discrètes
Soit \( (X,Y) \) un couple de variables aléatoires discrètes.
\( X \) et \( Y \) sont indépendantes si et seulement si, \( \forall A \subset X(\Omega ), B \subset Y(\Omega) \), on a : \( P( X\in A, Y \in B) = P(X \in A)P(Y \in B) \).
On peut généraliser ce résultat à une famille finie ou dénombrable de variables aléatoires.
Espérance d’une variable aléatoire discrète
Espérance
Soit \( X : \Omega \to \mathbb{R} \) une variable aléatoire discrète réelle telle que : \( X(\Omega )\) = {\( x_n : n\in I \)} où \( I \) est fini ou dénombrable.
On dit que \( X \) admet une espérance si la famille \( (x_n P(X = x_n))_{n \in I} \) est sommable. Dans ce cas, on appelle espérance de X, la somme de cette famille : \( E(X) = \displaystyle \sum _{n \in I} x_n P(X = x_n) \).
À retenir :
- L’espérance est linéaire.
- L’espérance est positive : Si \( X \ge 0 \) est d’espérance finie, alors \( E(X) \ge 0 \).
- Si \( |Y| \le X \) et \( X \) d’espérance finie, alors \( Y \) est d’espérance finie.
Espérance du produit de deux variables aléatoires indépendantes
Soit \( (X,Y) \) un couple de variables aléatoires discrètes.
Si \( X \) et \( Y \) sont indépendantes et admettent une espérance, alors \( XY \) admet une espérance et \( E(XY) = E(X)E(Y) \).
De même, on peut généraliser le résultat à une famille finie ou dénombrable de variables aléatoires.
Espérance conditionnelle – formule de l’espérance totale
Soit \( A \in \mathcal{A} \) un évènement de probabilité strictement positive et \( X \) une variable aléatoire réelle et discrète. On note \( X(\Omega ) =\) {\( x_i ; i\in I\)}.
On dit que \( X \) possède une espérance conditionnelle finie notée \( E_{A}(X) \) si \( X \) possède une espérance finie pour la probabilité conditionnelle \( P_A \). C’est le cas si et seulement si, la série \( \displaystyle \sum_{i \in I} x_i P_A(X=x_i) \) est absolument convergente.
On a alors : \( E_A(X) = \displaystyle \sum_{i \in I} x_i P_A(X=x_i) \).
Formule de l’espérance totale
Soit \( X \) une variable aléatoire discrète définie sur \( (\Omega , \mathcal{A}, P ) \) et \( (A_n)_{n \in \mathbb{N}}\) un système complet d’évènements. On note \( J := \) {\( n\in \mathbb{N} : P(A_n) \ne 0 \)}.
Alors \( X \) admet une espérance finie si et seulement si la série \( \displaystyle \sum_{(x,n) \in X(\Omega) \times J} xP_{A_n}(X=x)P(A_n) \) converge absolument.
Dans ce cas : \( \forall n \in J, E_{A_n}(X) \) est définie et \( E(X) = \displaystyle \sum_{n \in J} E_{A_n}(X) P(A_n) \).
Théorème de transfert
Soit \( f \) définie sur \( X(\Omega ) \) et à valeurs dans \( \mathbb{R} \).
\( f(X) \) est d’espérance finie si et seulement si la famille \( P(X=x_n)f(x_n))_{n \in I} \) est sommable. Dans ce cas, on a : \( E(f(X)) = \displaystyle \sum_{n \in I} f(x_n)P(X=x_n) \).
Inégalité de Markov
Soit \( X : \Omega \to \mathbb{R} \) une variable aléatoire discrète réelle, d’espérance finie.
\[ \forall \epsilon > 0 , P(|X| \ge \epsilon ) \le \frac{E(|X|)}{\epsilon} \].
Inégalité de Cauchy-Schwarz
Si \( X \) et \( Y \) admettent des moments d’ordre 2, alors \( XY \) est d’espérance finie et \( (E(XY))^2 \le E(X^2)E(Y^2) \).
Variance – écart-type
Soit \( X : \Omega \to \mathbb{R} \) une variable aléatoire discrète réelle définie sur \( (\Omega , \mathcal{A}, P ) \).
Si \( X \) admet un moment d’ordre 2, on appelle variance de \( X \) le moment centré d’ordre 2 : \( V(X) = E((X-E(X))^2) \).
On appelle écart-type de \( X \) noté \( \sigma (X)\), la quantité : \( \sigma (X) = \displaystyle \sqrt{V(X)}\).
Propriétés :
- \( \forall a,b \in \mathbb{R}, V(aX + b) = a^2V(X) \)
- si \( X_1, …, X_n \) sont des variables aléatoires admettant des moments d’ordre 2. Alors on a l’égalité : \[ V( \displaystyle \sum_{i=1}^{n} X_i ) = \displaystyle \sum_{i=1}^{n} V(X_i) + 2 \displaystyle \sum_{i \le i < j \le n}^{n} (E(x_i X_j) – E(X_i)E(X_j) \].
- Formule de König-Huyghens : \( V(X) = E(X^2) – (E(X))^2 \)
Inégalité de Bienaymé-Tchebychev
Soit \( X : \Omega \to \mathbb{R} \) une variable aléatoire discrète réelle d’espérance \( m \) et d’écart-type \( \sigma \).
Alors, \( \forall \epsilon > 0, P(|X-m| \ge \epsilon) \le \frac{\sigma ^2}{\epsilon ^2}\).
Couple de variables aléatoires
Soient \( X,Y : \Omega \to \mathbb{R} \) deux variables aléatoires discrètes réelles définies sur \( \Omega \). On note \( X(\Omega ) := \) {\( a_i ; i \in I \)} et \( Y(\Omega ) := \) {\( b_j ; i \in J \)}, \( I \) et \( J \) au plus dénombrables (fini ou dénombrable).
On appelle \( (X,Y) \), couple de variables aléatoires discrètes, où \( (X,Y)(\Omega ) \subset X(\Omega ) \times Y(\Omega) \).
On appelle loi du couple ou loi conjointe l’application \( (i,j) \mapsto P((X=a_i) \cup (Y=b_j)) \).
On appelle lois marginales du couple \( (X,Y) \) les lois de probabilités des variables \( X \) et \( Y \) :
- \( \forall i \in I , P(X=a_i) = \displaystyle \sum_{j \in J} P((X=a_i) \cup (Y=b_j)) \).
- \( \forall j \in J , P(X=b_j) = \displaystyle \sum_{i \in I} P((X=a_i) \cup (Y=b_j)) \).
Théorème : Soit \( f : X(\Omega ) \times Y(\Omega ) \to \mathbb{R} \) une application. On note \( Z := (X,Y) \). \( Z \) admet une espérance si et seulement si, la famille \( (f(a_i,b_j)P((X=a_i) \cup (Y=b_j)))_{(i,j) \in I \times J} \) est sommable.
Dans ce cas : \( E(f(Z)) = \displaystyle \sum_{(i,j) \in I \times J} f(a_i,b_j)P((X=a_i) \cup (Y=b_j)) \).
Covariance – coefficient de corrélation linéaire
Soient \( X,Y : \Omega \to \mathbb{R} \) deux variables aléatoires discrètes réelles définies sur \( \Omega \).
Si \( X \) et \( Y \) admettent des moments d’ordre 2, alors la covariance de \( X \) et \( Y \) est définie par : \( cov(X,Y) = E((X-E(X))(Y-E(Y))) = E(XY) – E(X)E(Y) \).
On a alors : si \( X_1, …, X-n \) sont des variables aléatoires admettant des moments d’ordre 2.
\[ V( \displaystyle \sum_{i=1}^{n} X_i ) = \displaystyle \sum_{i=1}^{n} V(X_i) + 2 \displaystyle \sum_{i \le i < j \le n}^{n} (E(x_i X_j) – E(X_i)E(X_j) = \displaystyle \sum_{i=1}^{n} V(X_i) + 2 \displaystyle \sum_{i \le i < j \le n}^{n} cov(X_i, X-j \].
Le coefficient de corrélation linéaire de \( X \) et \( Y \) supposées non quasi-constantes est définie par : \( \rho (X,Y) = \frac{cov(X,Y)}{\sigma (X) \sigma(Y)} \).
Loi discrètes usuelles
Loi uniforme discrète
Soient \( x_1, … , x_n \in \mathbb{R} \).
On dit qu’une variable aléatoire \( X \) suit une loi uniforme discrète sur {\( x_1 , … , x_n \)} si :
- \( X(\Omega ) \) = {\( x_1 , … , x_n \)}
- \( P(X=x_1) = P(X=x_2) = … = P(X=x_n) = \frac{1}{n} \)
On a alors : \( E(X) = \frac{1}{n} \displaystyle \sum_{i=1}^{n}x_i \) et \( V(X) = \frac{1}{n} (\displaystyle \sum_{i=1}^{n}x_i^2 ) – (E(X))^2\)
Loi de Bernoulli
On dit qu’une variable aléatoire \( X \) suit une loi de Bernoulli de paramètre \( p \in ]0,1[ \) et on note \( X \hookrightarrow \mathcal{B}(p) \) si :
- \( X(\Omega ) \) = {0,1}
- \( P(X=1) = p \) et \( P(X=0) = 1 – p \)
On a alors : \( E(X) = p \) et \( V(X) = p(1-p) \)
Loi binomiale
On dit qu’une variable aléatoire \( X \) suit une loi Binomiale de paramètre \( n \ge 1 \) et \( p \in ]0,1[ \) et on note \( X \hookrightarrow \mathcal{G}(p) \) si :
- \( X(\Omega ) \) = {\(0,1,…, n \)}
- \( \forall k \in X(\Omega ), P(X=k) = C_{k}^{n}p^k(1-p)^{n-k} \)
On a alors : \( E(X) = np \) et \( V(X) = np(1-p) \)
Loi géométrique
On dit qu’une variable aléatoire \( X \) suit une loi géométrique de paramètre \( p \in ]0,1[ \) et on note \( X \hookrightarrow \mathcal{B}(n,p) \) si :
- \( X(\Omega ) = \mathbb{N}^* \)
- \( \forall k \in X(\Omega ), P(X=k) = p(1-p)^{k-1} \)
On a alors : \( E(X) = \frac{1}{p} \) et \( V(X) = \frac{1-p}{p^2} \)
Loi de poisson
On dit qu’une variable aléatoire \( X \) suit une loi de poisson de paramètre \( \lambda > 0 \) et on note \( X \hookrightarrow \mathcal{P}(\lambda) \) si :
- \( X(\Omega ) = \mathbb{N} \)
- \( \forall k \in X(\Omega ), P(X=k) = e^{- \lambda} \frac{\lambda ^k}{k!} \)
On a alors : \( E(X) = \lambda \) et \( V(X) = \lambda \)
Variable aléatoire à densité
On dit que \( X : \Omega \to \mathbb{R} \) est une variable aléatoire à densité s’il existe une fonction \( f : \mathbb{R} \to \mathbb{R} \) continue par morceaux qui vérifie : \( \forall a<b, P(X \in [a,b]) = \displaystyle \int_{a}^{b} f(t) \, \mathrm{d}t \).
Lorsqu’une telle fonction \(f\) existe, elle est appelée densité de la variable aléatoire \( X \).
Fonction de répartition
Soit \( X \) une variable aléatoire sur \( (\Omega , \mathcal{A}, P ) \). On appelle fonction de répartition de \( X \) la fonction : \( F : \begin{cases} \mathbb{R} \to \mathbb{R} \\ x \mapsto P(X \le x) \end{cases} \).
\( F \) vérifie les propriétés suivantes :
- \( \forall x \in \mathbb{R}, 0 \le F(x) \le 1 \).
- \( F \) est croissante.
- \( \lim \limits_{x \to -\infty} F(x) = 0 \) et \( \lim \limits_{x \to +\infty} F(x) = 1 \).
- \( F \) est continue à droite.
Densité de probabilité
Soit \( f \) une fonction définie sur \( \mathbb{R} \).
\( f \) est la densité d’une variable aléatoire \( X \) si et seulement si elle vérifie :
- \( f \) est à valeurs positives.
- \( f \) est continue sur \( \mathbb{R} \) sauf éventuellement en un nombre fini de points.
- \( \displaystyle \int_{-\infty}^{+ \infty} f(t) \, \mathrm{d}t \) converge et vaut 1.
Espérance
Espérance d’une variable aléatoire à densité
Soit \( X : \Omega \to \mathbb{R} \) une variable aléatoire admettant une densité \( f \).
On dit que \( X \) admet une espérance si l’intégrale \( \displaystyle \int_{-\infty}^{+
\infty} tf(t) \, \mathrm{d}t \) converge absolument. Dans ce cas, on appelle espérance de X le réel défini par : \( E(X) = \displaystyle \int_{- \infty}^{+ \infty} tf(t) \, \mathrm{d}t \).
On retrouve les mêmes propriétés que pour l’espérance d’une variable aléatoire discrète.
Théorème de transfert
Soit \( X \) une variable aléatoire admettant \( f \) pour densité. Soit \( \phi : \Omega \to \mathbb{R} \) une fonction continue.
Si \( \displaystyle \int_{-\infty}^{+\infty} |\phi (t) | f(t) \, \mathrm{d}t \) converge, \( \; \) alors la variable aléatoire \( \phi (X) \) admet une espérance qui vaut : \( E(\phi (X)) = \displaystyle \int_{-\infty}^{+\infty} \phi (t) f(t) \, \mathrm{d}t \).
Variance et moments
Soit \( X \) une variable aléatoire admettant \( f \) pour densité.
On dit que \( X \) possède un moment d’ordre \( r \in \mathbb{N}^* \) si l’intégrale \( \displaystyle \int_{-\infty}^{+ \infty} t^r f(t) \, \mathrm{d}t\) est (absolument) convergente.
On dit que \( X \) possède une variance finie si et seulement si, \( X \) possède un moment d’ordre 2.
Quelques propriétés sur les variables aléatoires à densité
Soient \( X_1, …, X_n \) des variables aléatoires à densité définies sur un même espace probabilisé \( (\Omega , \mathcal{A}, P ) \).
Lemme des coalitions : Si \( X_1, …, X_n \) sont des variables mutuellement indépendantes, alors \( \forall p \in [\![1,n]\!] \), toute variable aléatoire fonction de \( p \) variables aléatoires parmi les précédentes est indépendante de toute variable aléatoire fonction des \( (n-p) \) variables aléatoires restantes.
Théorème – formule de convolution : Soient \( X , Y \) deux variables aléatoires indépendantes de densités respectives \( f_{X} , f_{Y} \).
Si la fonction \( h(x) = \displaystyle \int_{-\infty}^{+\infty} f_{X}(x-t)f_{Y}(t) \, \mathrm{d}t \) définit une fonction continue sur \( \mathbb{R} \) privé éventuellement d’un nombre fini de points, alors la variable aléatoire \( Z = X + Y \) est à densité et h en est une.
De cela on déduit la propriété de stabilité de la loi normale.
Lois usuelles
Loi uniforme
Soient \( a,b \in \mathbb{R} \).
On dit qu’une variable aléatoire \( X \) suit la loi uniforme sur \( [a,b] \) et on note \( X \hookrightarrow \mathcal{U}([a,b]) \) si elle admet pour densité :
\[ f(x) = \mathbb{1}_{[a,b]}(x) \frac{1}{b-a} \].
On a alors : \( E(X) = \frac{a+b}{2} \) et \( V(X) = \frac{(b-a)^2}{12} \).
Loi normale
On dit qu’une variable aléatoire \( X \) suit la loi normale de paramètres \( \mu \) et \( \sigma ^2 \) et on note \( X \hookrightarrow \mathcal{N}(\mu, \sigma^2) \) si elle admet pour densité :
\[ f(x) = \frac{1}{\sigma \sqrt(2 \pi)} \exp(- \frac{(x-\mu )^2}{2 \sigma ^2}) \].
On a alors : \( E(X) = \mu \) et \( V(X) = \sigma ^2 \).
Loi exponentielle
On dit qu’une variable aléatoire \( X \) suit la loi exponentielle de paramètres \( \lambda >0 \) et on note \( X \hookrightarrow \mathcal{E}(\lambda) \) si elle admet pour densité :
\[ f(x) = \mathbb{1}_{]0, +\infty [}(x) \lambda e^{-\lambda} \].
On a alors : \( E(X) = \frac{1}{\lambda} \) et \( V(X) = \frac{1}{\lambda ^2} \).
\( X \hookrightarrow \mathcal{E}(\lambda) \) si et seulement si, \( X \) est sans mémoire, c’est-à-dire : \( \forall t, t’ >0, P_{X>t’}(X>t+t’) = P(X>t) \).
Loi gamma
On dit qu’une variable aléatoire \( X \) suit la loi gamma de paramètres \( p >0, \lambda >0 \) et on note \( \Gamma (p, \lambda) \) si elle admet pour densité :
\[ f(x) = \mathbb{1}_{[0, +\infty [} (x) \frac{\lambda}{\Gamma (p)} e^{-\lambda x} (\lambda x)^{p-1} \].
On a alors : \( E(X) = \frac{p}{\lambda} \) et \( V(X) = \frac{p}{\lambda ^2} \).
Voilà ! J’espère que cet article de Major-Prépa te permettra d’y voir plus clair sur les probabilités, et plus si affinités. N’hésite pas à consulter nos autres articles pour acquérir les méthodes en mathématiques afin de devenir un·e chef·fe !