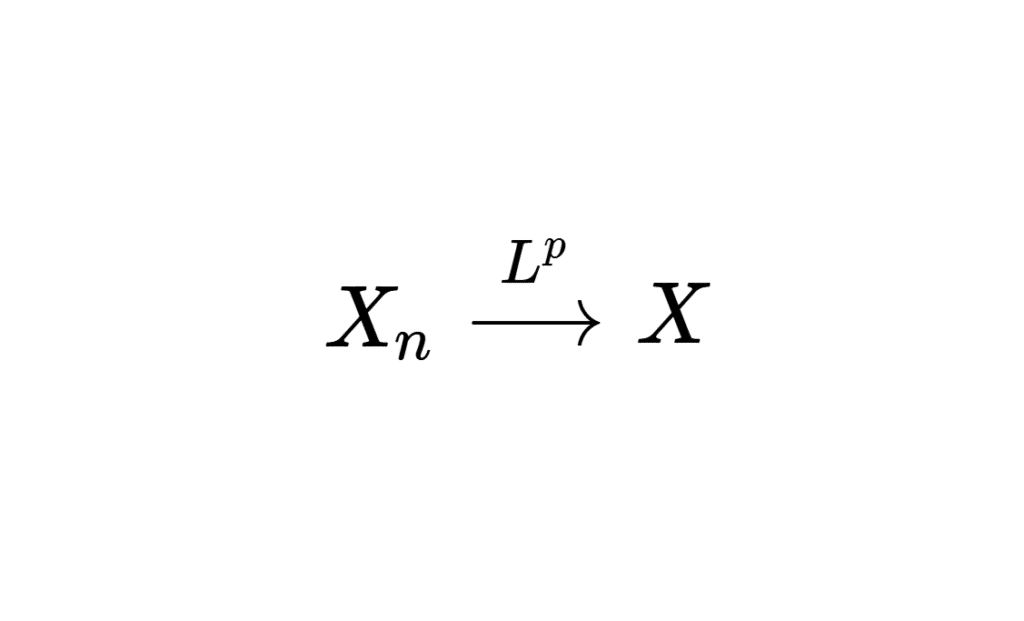
Il sera question ici de la convergence en moyenne d’ordre p des variables aléatoires. Tu connais déjà certains modes de convergence : par exemple, la convergence en probabilité ou la convergence en loi. À la différence de ces dernières, cette notion n’est encore jamais apparue aux écrits et peut pourtant faire l’objet d’un sujet intéressant !
Introduction
Dans le programme, il y a notamment la convergence en probabilité et la convergence en loi. Dans cet article, nous allons aborder un autre mode de convergence des variables aléatoires réelles : la convergence en moyenne d’ordre p (également appelée convergence \(L^p\)).
Il pourra ainsi être intéressant, en vue d’un sujet de type Maths II ou oral ESCP/HEC, de connaître la définition de ce mode de convergence et son lien avec les autres modes de convergence des variables aléatoires au programme.
Étudions donc la définition de la convergence en moyenne d’ordre \(p\), avant de dresser ses propriétés et notamment ses liens avec les autres modes de convergence. Nous finirons par quelques questions classiques assez abordables de type début de sujet Maths II.
Définition
Soit \( (X_n)_{n \in \mathbb{N}} \) une suite de variables aléatoires et \( X \) une variable aléatoire. On dit que \( X_n \) converge en moyenne d’ordre \( p \) vers \( X \), noté \( X_n \overset{L^p}{\longrightarrow} X \) si :
\[
\lim_{n \to \infty} \mathbb{E}[|X_n – X|^p] = 0
\]
Cas particuliers de la définition : lorsque \( p = 1 \), il s’agit de la convergence en moyenne et pour \( p = 2 \), on parle de convergence en moyenne quadratique.
Propriétés
Liens entre les convergences en moyenne d’ordres p et q
Si \( X_n \overset{L^p}{\longrightarrow} X \) pour un certain \( p \), alors \( X_n \overset{L^q}{\longrightarrow} X \) pour tout \( q \leq p \).
Nous ne démontrerons pas cette propriété, car ce n’est pas le sujet de cet article et que celle-ci fait intervenir une notion hors programme supplémentaire (l’inégalité de Jensen appliquée à des variables aléatoires).
Convergence en moyenne d’ordre p et convergence en probabilité
On peut retenir de manière littérale la propriété suivante : la convergence en moyenne implique la convergence en probabilité, cette dernière impliquant elle-même la convergence en loi. Dans le cadre de cet article, nous nous intéresserons seulement au lien entre convergence en moyenne et convergence en loi, mais il est souvent utile de connaître la seconde implication mentionnée ci-dessus.
Voici un rapide rappel de la notion de convergence en probabilité avant de poursuivre.
Une suite de variables aléatoires \( (X_n) \) converge en probabilité vers \( X \) si pour tout \( \epsilon > 0 \) :
\[
\lim_{n \to \infty} \mathbb{P}(|X_n – X| \geq \epsilon) = 0
\]
Démontrons alors que la convergence en moyenne d’ordre \( p \) implique la convergence en probabilité.
Démonstration
Pour montrer que la convergence en moyenne d’ordre \( p \) implique la convergence en probabilité, nous utilisons l’inégalité de Markov.
Pour toute variable aléatoire non négative \( Y \) et tout \( a > 0 \),
\[
\mathbb{P}(Y \geq a) \leq \frac{\mathbb{E}[Y]}{a}
\]
Soit \( \epsilon > 0 \). Appliquons l’inégalité de Markov à \( |X_n – X|^p \) qui a le goût d’être effectivement positive :
\[
\mathbb{P}(|X_n – X| \geq \epsilon) = \mathbb{P}(|X_n – X|^p \geq \epsilon^p) \leq \frac{\mathbb{E}[|X_n – X|^p]}{\epsilon^p}
\]
Puisque \( \mathbb{E}[|X_n – X|^p] \to 0 \), lorsque \( n \to \infty \), nous avons :
\[
\lim_{n \to \infty} \frac{\mathbb{E}[|X_n – X|^p]}{\epsilon^p} = 0
\]
Donc, pour tout \( \epsilon > 0 \),
\[
\lim_{n \to \infty} \mathbb{P}(|X_n – X| \geq \epsilon) = 0
\]
Ce qui montre que \( (X_n) \) converge en probabilité vers \( X \).
Linéarité
Si \( X_n \overset{L^p}{\longrightarrow} X \) et \( Y_n \overset{L^p}{\longrightarrow} Y \), alors pour tous réels \(a\) et \(b\), \( aX_n + bY_n \overset{L^p}{\longrightarrow} aX + bY \).
La démonstration de cette propriété nécessite l’inégalité de Minkowski (hors programme), nous admettrons donc cette dernière.
Lien avec la convergence en loi
La propriété est claire : la convergence en moyenne d’ordre p implique la convergence en loi.
En se basant sur ce que tu as vu précédemment dans l’article, la démonstration est aisée ! Nous avons montré que la convergence en moyenne d’ordre p implique la convergence en probabilité. Mais, d’après le cours de deuxième année, la convergence en probabilité implique la convergence en loi, ce qui achève la démonstration !
Questions classiques
Exercice 1 : petit exercice abordable pour s’échauffer
Soit \( (X_n)_{n \in \mathbb{N}} \) une suite de variables aléatoires telles que \( X_n \sim \mathcal{N}(0, \frac{1}{n}) \). Montrer que \( X_n \) converge en moyenne d’ordre 2 vers 0.
Solution
Calculons \( \mathbb{E}[|X_n – 0|^2] \) :
\[
\mathbb{E}[|X_n – 0|^2] = \mathbb{E}[X_n^2] = \text{Var}(X_n) = \frac{1}{n}
\]
Or :
\[
\lim_{n \to \infty} \frac{1}{n} = 0
\]
Cela conclut l’exercice puisque \(\mathbb{E}[|X_n-0|^2] = 0 \)
Question 2 : difficulté moyenne
Soit \( (X_n)_{n \in \mathbb{N}} \) une suite de variables aléatoires i.i.d. avec \( \mathbb{E}[X_n] = \mu \) et \( \text{Var}(X_n) = \sigma^2 \). Montrer que la moyenne empirique \( \bar{X}_n = \frac{1}{n} \sum_{i=1}^n X_i \) converge en moyenne d’ordre 2 vers \( \mu \).
Solution
Calculons \( \mathbb{E}[|\bar{X}_n – \mu|^2] \) :
\[
\mathbb{E}[|\bar{X}_n – \mu|^2] = \text{Var}(\bar{X}_n).
\]
Puisque les \( X_i \) sont i.i.d.,
\[
\text{Var}(\bar{X}_n) = \frac{\sigma^2}{n}.
\]
En prenant la limite lorsque \( n \to \infty \),
\[
\lim_{n \to \infty} \mathbb{E}[|\bar{X}_n – \mu|^2] = \lim_{n \to \infty} \frac{\sigma^2}{n} = 0.
\]
Donc, \( \bar{X}_n \overset{L^2}{\longrightarrow} \mu \).
Question 3 : convergence d’une suite bornée (exercice exigeant)
Soit \( (X_n)_{n \in \mathbb{N}} \) une suite de variables aléatoires bornées par une constante \( M \) telle que \( |X_n| \leq M \) pour tout \( n \). Si \( X_n \overset{p}{\longrightarrow} X \), montrer que \( X_n \overset{L^1}{\longrightarrow} X \).
Indice : on pourra penser à la décomposition suivante : \(
\mathbb{E}[|X_n – X|] = \mathbb{E}[|X_n – X| \cdot \mathbf{1}_{\{|X_n – X| < \epsilon\}}] + \mathbb{E}[|X_n – X| \cdot \mathbf{1}_{\{|X_n – X| \geq \epsilon\}}]
\) après l’avoir justifiée.
Solution
Puisque \( X_n \overset{p}{\longrightarrow} X \), cela signifie que pour tout \( \epsilon > 0 \),
\[
\lim_{n \to \infty} P(|X_n – X| \geq \epsilon) = 0.
\]
Comme \( |X_n| \leq M \) pour tout \( n \), on a \( |X_n – X| \leq 2M \).
Considérons \( \mathbb{E}[|X_n – X|] \). Nous pouvons écrire :
\[
\mathbb{E}[|X_n – X|] = \mathbb{E}[|X_n – X| \cdot \mathbf{1}_{\{|X_n – X| < \epsilon\}}] + \mathbb{E}[|X_n – X| \cdot \mathbf{1}_{\{|X_n – X| \geq \epsilon\}}].
\]
La première partie est bornée par \( \epsilon \) :
\[
\mathbb{E}[|X_n – X| \cdot \mathbf{1}_{\{|X_n – X| < \epsilon\}}] \leq \epsilon.
\]
La deuxième partie est bornée par \( 2M \cdot P(|X_n – X| \geq \epsilon) \) d’après l’argument de la majoration de \( |X_n – X|\) :
\[
\mathbb{E}[|X_n – X| \cdot \mathbf{1}_{\{|X_n – X| \geq \epsilon\}}] \leq 2M \cdot P(|X_n – X| \geq \epsilon).
\]
En prenant la limite lorsque \( n \to \infty \), nous avons :
\[
\lim_{n \to \infty} \mathbb{E}[|X_n – X|] \leq \epsilon + 2M \cdot \lim_{n \to \infty} P(|X_n – X| \geq \epsilon) = \epsilon.
\]
Puisque \( \epsilon \) est arbitrairement petit, cela implique que :
\[
\lim_{n \to \infty} \mathbb{E}[|X_n – X|] = 0.
\]
Donc, \( X_n \overset{L^1}{\longrightarrow} X \).
Exercice très technique, donc ce n’est pas grave si tu n’as pas réussi, l’essentiel est déjà de s’accrocher lors de la correction !
Conclusion
La notion de convergence en moyenne d’ordre p, bien qu’elle soit hors programme, complète et précise les deux modes de convergence des variables aléatoires au programme (convergence en loi, convergence en probabilité). Ainsi, un sujet de Parisienne pourrait se consacrer à l’étude de la convergence \(L^p\) en la liant à ses liens avec les deux autres modes de convergence au programme.
Il n’y a plus qu’à te souhaiter qu’un tel sujet tombe, toi qui es désormais à l’aise avec cette notion.
Tu peux retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux également accéder ici à toutes nos autres ressources mathématiques !