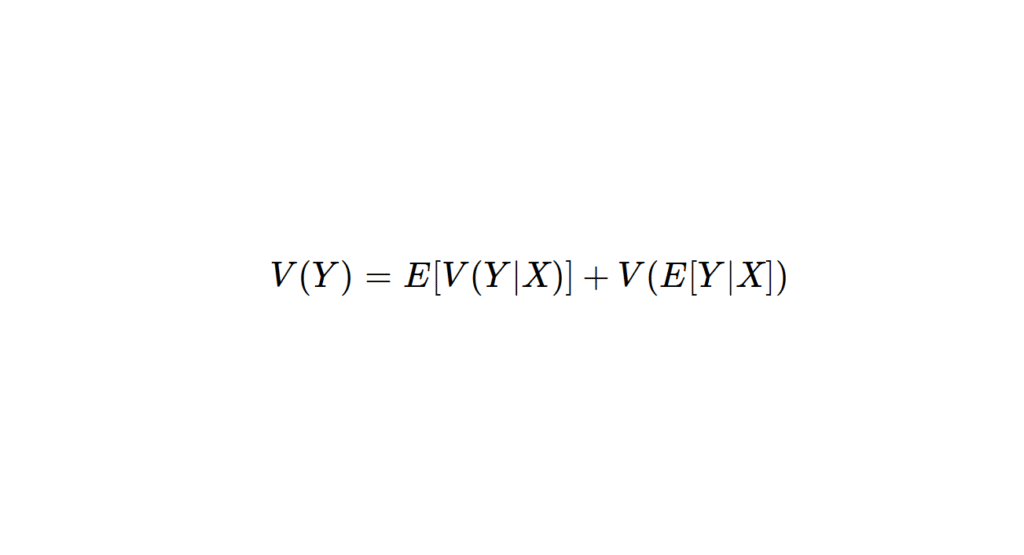
La formule d’Eve (ou formule de la décomposition de la variance) est une alliée redoutable pour calculer des variances complexes sans s’épuiser dans des calculs d’intégrales doubles ou de sommes infinies. Elle permet de calculer la variance d’une variable aléatoire \( Y \) en « segmentant » l’information apportée par une autre variable \( X \). Retiens à cet égard que c’est l’outil privilégié dès que l’on fait face à un processus à deux étapes, apparaissant parfois dans les sujets de type Maths II ou encore dans les oraux mathématiques parisiens. Nous allons d’abord revenir sur la notion de variance conditionnelle, avant de présenter la formule d’Eve et de la démontrer. Nous l’appliquerons ensuite à deux problèmes probabilistes pour montrer sa pertinence et nous familiariser avec son utilisation.
Remarque : Pourquoi « Eve » ?
Le nom Eve est un moyen mnémotechnique basé sur l’écriture anglaise de la formule : Expectation of Variance plus Variance of Expectation.
\[ E-V-V-E \longrightarrow \text{Eve} \]
Notion préliminaire : la notion de variance conditionnelle
Pour bien comprendre la formule d’Eve, il faut d’abord comprendre l’objet mathématique \( V(Y|X) \).
La variance conditionnelle \( V(Y|X) \) est définie par :
\[ V(Y|X) = E[Y^2 | X] – (E[Y | X])^2 \] une application de la formule de Keonig-Huygens.
Attention à bien différencier \( V(Y|X=x) \), qui est un nombre réel (c’est la variance de la loi de \( Y \) sachant que \( X \) a pris la valeur précise \( x \)), de \( V(Y|X) \), qui est une variable aléatoire de \( X \).
\( V(Y|X) \) représente l’erreur que l’on commet en prédisant \( Y \) par son espérance conditionnelle \( E[Y|X] \), on parle alors d’incertitude résiduelle.
Notons d’ailleurs que Si \( X \) et \( Y \) sont indépendantes, alors \( V(Y|X) = V(Y) \).
La formule d’Eve
Raisonnement intuitif
Intuitons cette formule avec un exemple concret.
Imagine que tu veuilles calculer la variance des notes au concours pour l’ensemble des candidats français (\( Y \)). Tu peux segmenter ces candidats par leur lycée d’origine (\( X \)).
\( E[V(Y|X)] \) (Inertie intra-classe) : c’est la moyenne des variances des notes au sein de chaque lycée.
\( V(E[Y|X]) \) (Inertie inter-classe) : c’est la variance des moyennes des lycées.
La diversité totale des notes est la somme de la diversité à l’intérieur des groupes et de la diversité entre les groupes.
Formule
Soient \( X \) et \( Y \) deux variables aléatoires de carré intégrable. La formule d’Eve s’énonce :
\[ V(Y) = E[V(Y|X)] + V(E[Y|X]) \]
On arrive alors à définir la variance de \(Y\) comme une somme de deux variances où intervient la variable \(X\). Dans les énoncés qui mettent en œuvre des processus à deux étapes, on pourra alors connaître les valeurs de ces deux dernières.
Démonstration
Par application de la formule de Koenig-Huygens, comme nous avons pu le voir précédemment : \( V(Y|X) = E[Y^2|X] – (E[Y|X])^2 \).
En prenant l’espérance de cette formule précédente, par linéarité de l’espérance, nous avons : \( E[V(Y|X)] = E[E[Y^2|X]] – E[(E[Y|X])^2] \).
On peut ensuite démontrer que, par le théorème de l’espérance totale : \( E[E[Y^2|X]] = E[Y^2] \). Il s’agit ici d’une application directe de la formule de l’espérance totale sur laquelle nous ne reviendrons pas pour ne pas rallonger la démonstration.
On a donc :
(A) \( E[V(Y|X)] = E[Y^2] – E[(E[Y|X])^2] \)
Par Koenig-Huygens sur \( E[Y|X] \) :
(B) \( V(E[Y|X]) = E[(E[Y|X])^2] – (E[E[Y|X]])^2 = E[(E[Y|X])^2] – (E[Y])^2 \)
Conclusion
En sommant (A) et (B), les termes \( E[(E[Y|X])^2] \) s’annulent et par une ultime application de Koenig-Huygens, il reste :
\[ E[V(Y|X)] + V(E[Y|X]) = E[Y^2] – (E[Y])^2 = V(Y) \]
Exercices d’application
Variables discrètes
Énoncé : Une boutique reçoit \( N \) clients, avec \( N \sim \mathcal{P}(\lambda) \). Chaque client dépense une somme \( X_i \sim \mathcal{E}(\theta) \). Les \( (X_i) \) sont i.i.d. et indépendants de \( N \). Soit \( S = \sum_{i=1}^{N} X_i \). Calculer \( V(S) \).
Solution :
Si \( N=n \), alors \( S = \sum_{i=1}^n X_i \).
\( E[S|N=n] = n E[X_1] = \frac{n}{\theta} \Rightarrow E[S|N] = \frac{N}{\theta} \) (par linéarité de l’espérance et le fait que les \(X_i\) ont toutes la même espérance).
\( V(S|N=n) = n V(X_1) = \frac{n}{\theta^2} \Rightarrow V(S|N) = \frac{N}{\theta^2} \) (puisque les \(X_i\) sont i.i.d, la variance de leur somme est égale à la somme de leur variance respective, qui est connue, étant donné que toutes ces variables aléatoires suivent une loi exponentielle).
Application d’Eve :
\[ V(S) = E[V(S|N)] + V(E[S|N]) \]
\[ V(S) = E\left[ \frac{N}{\theta^2} \right] + V\left( \frac{N}{\theta} \right) = \frac{1}{\theta^2} E[N] + \frac{1}{\theta^2} V(N) \]
Comme \( E[N] = V(N) = \lambda \) (loi de Poisson) :
\[ V(S) = \frac{\lambda}{\theta^2} + \frac{\lambda}{\theta^2} = \frac{2\lambda}{\theta^2} \]
Voilà donc un cas classique d’application de la formule d’Eve qui permet de résoudre simplement un problème de détermination de la variance d’une variable aléatoire réelle.
Variables à densité
Énoncé : La durée de vie \( Y \) d’un composant électronique suit une loi \( \mathcal{E}(\Lambda) \), où le paramètre \( \Lambda \) est lui-même aléatoire et suit une loi uniforme \( \mathcal{U}([1, 2]) \). Calculer \( V(Y) \).
Résolution :
On débute par le calcul des différentes lois conditionnelles pour nous permettre de déterminer et de connaître l’espérance et la variance conditionnelle par la suite.
Sachant \( \Lambda = \lambda \), \( Y \sim \mathcal{E}(\lambda) \).
\( E[Y|\Lambda] = \frac{1}{\Lambda} \) et \( V(Y|\Lambda) = \frac{1}{\Lambda^2} \).
De plus, calculons les moments de \( \Lambda \) (car \( f_{\Lambda}(\lambda) = 1 \) sur \( [1,2] \)) :
\( E[V(Y|\Lambda)] = E\left[\frac{1}{\Lambda^2}\right] = \int_1^2 \frac{1}{\lambda^2} d\lambda = \left[ -\frac{1}{\lambda} \right]_1^2 = \frac{1}{2} \).
\( E[Y|\Lambda] = E\left[\frac{1}{\Lambda}\right] = \int_1^2 \frac{1}{\lambda} d\lambda = \ln(2) \).
\( V(E[Y|\Lambda]) = E\left[\frac{1}{\Lambda^2}\right] – (E\left[\frac{1}{\Lambda}\right])^2 = \frac{1}{2} – (\ln 2)^2 \).
Par application directe de la formule d’Eve, on obtient donc :
\[ V(Y) = \frac{1}{2} + \left( \frac{1}{2} – (\ln 2)^2 \right) = 1 – (\ln 2)^2 \]
Conclusion
En définitive, la formule d’Eve transforme donc un problème global complexe en deux sous-problèmes locaux censés être plus simples. En prépa, la clé est de savoir quand la sortir : dès qu’un énoncé présente une expérience « à tiroirs » ou une dépendance hiérarchique, la formule d’Eve pourra sûrement être utile.
Il est toutefois sûr que l’énoncé saura l’admettre ou alors te pousser à la démontrer grâce à des questions intermédiaires (format de type Maths II). Il n’y a donc plus qu’à croiser les doigts pour qu’elle tombe au concours maintenant qu’elle t’est familière !
Tu peux également retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux aussi accéder ici à toutes nos autres ressources mathématiques !