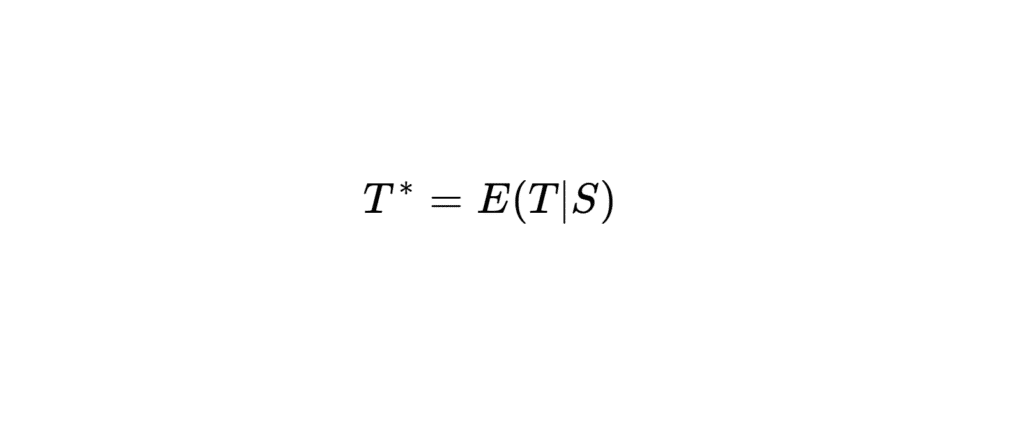
Dans le cadre du programme de mathématiques approfondies, la statistique inférentielle occupe une place prépondérante. Si la plupart des étudiants se familiarisent rapidement avec les notions de biais et de risque quadratique, un sommet théorique reste souvent méconnu ou redouté : le théorème de Rao-Blackwell. Ce dernier pourrait tout à fait intervenir dans un sujet de type Maths II, et se familiariser avec cette notion permet donc d’avoir une longueur d’avance si elle venait à tomber en concours. Ce théorème nous dit, en substance, que si l’on possède un estimateur médiocre mais sans biais, il existe une méthode systématique pour le transformer en un estimateur de meilleure qualité (de variance plus faible). C’est donc un outil tout à fait puissant que nous allons étudier ici.
Introduction
Avant de plonger dans le formalisme, rappelons l’objectif des estimateurs : nous voulons estimer un paramètre inconnu \(\theta\) d’une population à partir d’un échantillon \(X = (X_1, \dots, X_n)\).
Pour rappel
Un estimateur \(T\) est une variable aléatoire. Pour qu’il soit « bon », nous exigeons généralement deux propriétés :
- L’absence de biais : \(E_\theta(T) = \theta\). Cela signifie concrètement qu’en moyenne, l’estimateur estime la bonne valeur.
- Une variance minimale : plus la variance \(V_\theta(T)\) est faible, plus l’estimateur est précis autour de sa moyenne.
Le risque quadratique d’un estimateur sans biais se résume à sa variance. Le théorème de Rao-Blackwell intervient précisément ici : il permet de réduire la variance d’un estimateur sans biais sans en introduire un nouveau, comme nous avons commencé à le mentionner dans l’introduction de cet article.
La notion de statistique exhaustive
Une statistique est dite exhaustive (notée \(S\)) si elle « résume » toute l’information contenue dans l’échantillon concernant le paramètre \(\theta\). Une fois que l’on connaît la valeur de \(S\), connaître les valeurs individuelles de \(X_1, \dots, X_n\) n’apporte plus aucune information supplémentaire sur \(\theta\).
En pratique, la démonstration de l’exhaustivité d’une statistique peut être réalisée en invitant le candidat ECG via plusieurs sous-questions. Cette hypothèse semble néanmoins peu probable. Il est bien plus convaincant de penser qu’on admettra l’exhaustivité d’une statistique posée en énoncé, ce qui permettra alors de procéder comme ce qui suit.
Énoncé et démonstration du théorème
Soit \(T\) un estimateur sans biais du paramètre \(\theta\). Soit \(S\) une statistique exhaustive pour \(\theta\).
On définit un nouvel estimateur \(T^*\) par l’espérance conditionnelle :
\[ T^* = E(T | S) \]
Alors :
\(T^*\) est un estimateur de \(\theta\) (il ne dépend pas de \(\theta\) car \(S\) est exhaustive). Voir la définition d’un estimateur qu’il convient de connaître parfaitement !
\(T^*\) est sans biais : \(E_\theta(T^*) = \theta\).
\(V_\theta(T^*) \le V_\theta(T)\) pour tout \(\theta\).
L’inégalité est stricte sauf si \(T\) est déjà une fonction de \(S\) (auquel cas \(T = T^*\), dans ce cas, l’estimateur n’aura donc pas été amélioré).
Éléments de démonstration
La démonstration repose sur deux propriétés fondamentales de l’espérance et de la variance conditionnelles.
L’espérance totale
Grâce à la formule de l’espérance totale, on peut démontrer que : \(E(E(T|S)) = E(T)\).
Puisque \(E(T) = \theta\), alors on en déduit que \(E(E(T|S)) = \theta\) donc autrement dit que \(T^*\) est sans biais.
La décomposition de la variance
Cette formule est également appelée formule d’Eve et est hors programme, donc nous l’admettons ici pour les besoins de notre démonstration.
\[ V(T) = E(V(T|S)) + V(E(T|S)) \]
Comme \(V(T|S) \ge 0\)par définition de la variance, on a \(E(V(T|S)) \ge 0\), d’où :
\[ V(T) \ge V(E(T|S)) = V(T^*) \]
Application : l’exemple de la loi de Poisson
Soit \((X_1, \dots, X_n)\) un échantillon i.i.d. suivant une loi \(\mathcal{P}(\theta)\). On cherche à estimer \(g(\theta) = e^{-\theta} = P(X_1 = 0)\).
Estimateur initial : On pose \(T = \mathbb{1}_{\{X_1 = 0\}}\). On a bien \(E(T) = e^{-\theta}\).
Statistique exhaustive : On utilise \(S = \sum_{i=1}^n X_i\) que l’on répute être une statistique exhaustive pour les besoins de l’application du théorème Rao-Blackwell.
« Rao-Blackwellisation » : On calcule \(T^* = E(T | S) = P(X_1 = 0 | \sum X_i = S)\).
Par calcul, on obtient :
\[ T^* = \left( 1 – \frac{1}{n} \right)^S \]
L’estimateur \(T^*\) est bien plus performant que \(T\), car sa variance est nettement plus faible par Rao-Blackwell.
Quelques points de vigilance
Exhaustivité
Le théorème de Rao-Blackwell repose sur une hypothèse particulièrement importante qu’il convient de ne pas négliger : l’exhaustivité de \(S\). En pratique, il conviendra toujours de vérifier l’exhaustivité de \(S\) puisque, si tel n’est pas le cas, \(E(T|S)\) dépendra de \(\theta\) et ne sera pas un estimateur.
Espérance conditionnelle
Pour appliquer le théorème, on passe notamment par le calcul d’une espérance conditionnelle. Il convient donc absolument de bien connaître la formule au programme : \(E(X|S=s) = \sum x P(X=x|S=s)\).
Conclusion
L’utilité du théorème de Rao-Blackwell peut ainsi se résumer en deux points clés :
- L’optimisation systématique. Il fournit une recette infaillible pour transformer un estimateur « grossier » (fondé sur une seule donnée) en un estimateur plus satisfaisant (fondé sur toute l’information utile via une statistique exhaustive).
- La réduction de la variance. On obtient ainsi un estimateur plus précis en réduisant la variance de l’estimateur initial, sans pour autant créer de biais.
Tu peux retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux également accéder ici à toutes nos autres ressources mathématiques !