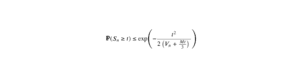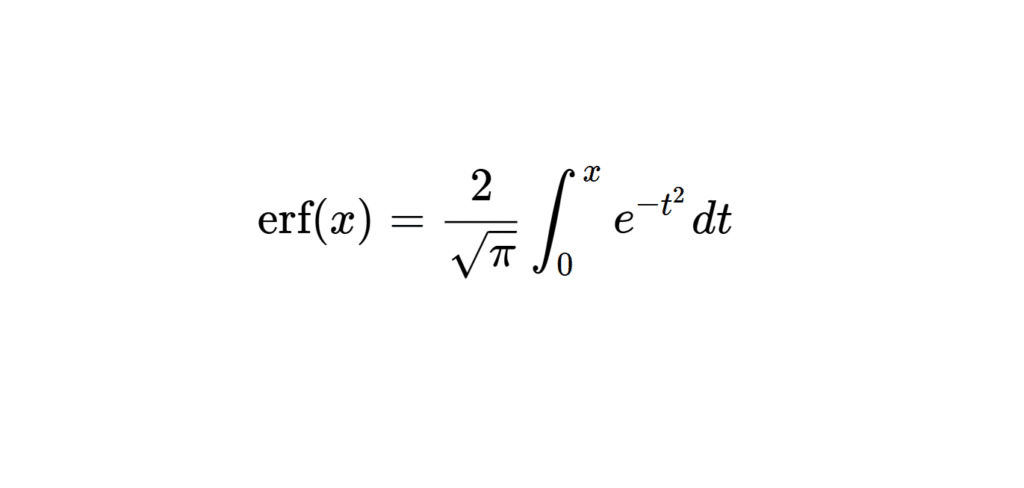
La fonction d’erreur, souvent désignée sous le nom « erf », est une fonction qui exprime l’intégrale de la fonction gaussienne et intervient fréquemment dans les calculs de probabilité et d’estimation d’intervalle. De ce fait, celle-ci pourrait faire l’objet d’un sujet de type Maths I ou Maths II ou, tout du moins, être abordée dans ce type de sujet. Cet article présente la fonction d’erreur, ses propriétés principales et fait le lien avec l’étude de la loi normale, véritable pilier de l’étude des probabilités en deuxième année de prépa.
Définition
Fonction d’erreur
La fonction d’erreur est définie comme suit :
\[
\text{erf}(x) = \frac{2}{\sqrt{\pi}} \int_0^x e^{-t^2} dt
\]
Cette définition montre que la fonction d’erreur est l’intégrale de la fonction gaussienne \( e^{-t^2} \), multipliée par un facteur constant \( \frac{2}{\sqrt{\pi}} \). Elle est donc directement liée à la distribution normale standard, que tu as peut-être déjà vue avec ton prof en cours.
Voici un graphique de cette fonction sur l’intervalle \([-3;3]\) :
Fonction d’erreur complémentaire (erfc)
Il est également important de mentionner cette fonction annexe à la fonction d’erreur classique qui va nous aider par la suite à comprendre les propriétés de la fonction d’erreur.
Cette dernière est ainsi définie comme suit :
\[ \text{erfc}(x) = \frac{2}{\sqrt{\pi}} \int_x^{\infty} e^{-t^2} \, dt
\]
Ainsi, si elle est dite « complémentaire », c’est parce que la somme des deux fonctions est toujours égale à \(1\).
Cette fonction est également utilisée pour calculer des probabilités dans les distributions normales, en particulier dans les cas où l’on souhaite évaluer la probabilité que la variable aléatoire dépasse une certaine valeur. En effet, la fonction d’erreur complémentaire représente la « queue » de la distribution normale.
Une autre façon de relier les deux fonctions est la suivante :
\[
\text{erf}(x) = 1 – \text{erfc}(x)
\]
Cela montre que la fonction d’erreur et la fonction d’erreur complémentaire sont étroitement liées et que leur utilisation dépend de la convention choisie pour l’expression de la probabilité.
Propriétés
Fonction de répartition et lien avec la loi normale
La fonction de répartition \( \Phi \) de la loi normale centrée réduite (c’est-à-dire une variable aléatoire suivant une distribution normale de moyenne 0 et de variance 1) peut être exprimée à l’aide de la fonction d’erreur :
\[
\Phi(x) = \frac{1}{2} \left[ 1 + \text{erf}\left(\frac{x}{\sqrt{2}}\right) \right] (*)
\]
Il est possible de démontrer cette expression en partant directement de la définition de \(
\Phi(z) = \int_{-\infty}^{z} \frac{1}{\sqrt{2\pi}} e^{-\frac{t^2}{2}} \, dt\) (indice : il s’agit ensuite d’écrire le réel \(1\) en fonction de la fonction d’erreur et la fonction d’erreur complémentaire).
Ainsi, la fonction d’erreur permet de calculer les probabilités pour une variable suivant une loi normale. En utilisant la fonction d’erreur complémentaire, on peut aussi obtenir la probabilité que la variable aléatoire soit supérieure à une certaine valeur et même comprise dans un intervalle symétrique de type \([-z, z]\).
La probabilité pour qu’une variable normale centrée réduite \(X\) prenne une valeur dans l’intervalle \([-z, z]\) est :
\[erf\left( \frac{z}{\sqrt{2}} \right) = \mathbb{P}(X \in [-z, z]).
\]
La fonction de répartition de \(X\), ou fonction de répartition de la loi normale, usuellement notée \(\Phi\) , est liée à la fonction d’erreur, par la relation :
\[erf(z) = 2\Phi(z\sqrt{2}) – 1.
\]
Remarquons que pour obtenir une telle expression, on arrange directement \((*)\).
Image de la fonction d’erreur
La fonction d’erreur possède plusieurs propriétés intéressantes concernant son image.
La fonction d’erreur prend ses valeurs dans l’intervalle \( [-1, 1] \). En effet, on a :
\[
\lim_{x \to +\infty} \text{erf}(x) = 1 \quad \text{et} \quad \lim_{x \to -\infty} \text{erf}(x) = -1
\]
(Cela fait appel à la valeur de l’intégrale de Gauss qui est hors programme, mais que tu connais peut-être déjà.)
Concernant le comportement asymptotique de la fonction d’erreur complémentaire, celle-ci se rapproche de \( 0 \) à mesure que \( x \to +\infty \) (simple à démontrer en revenant à la relation qui relie la fonction d’erreur et la fonction d’erreur complémentaire, puisque l’on connaît la limite de la fonction \(erf\)).
Symétrie
La fonction d’erreur est une fonction impaire, ce qui signifie que :
\[
\text{erf}(-x) = -\text{erf}(x)
\]
Cette propriété découle de la symétrie de la fonction gaussienne \( e^{-t^2} \). Pour démontrer cette propriété, on peut procéder au changement de variable \(u=-t\) (où \(t\) est la variable d’intégration telle que présentée dans la définition de la fonction d’erreur dans la partie I de cet article).
Développement en série
Tu connais déjà (si tu es en deuxième année) le développement en série de certaines fonctions, comme la fonction exponentielle par exemple. De la même manière, il est possible de donner un développement en série de la fonction d’erreur. On a donc la relation suivante :
\[
\mathrm{erf}(x) = \frac{2}{\sqrt{\pi}} \sum_{n=0}^{\infty} \frac{(-1)^n}{(2n+1) \cdot n!} x^{2n+1}
\]
Dans le programme de maths appliquées comme en maths approfondies, l’étude des développements en série est assez limitée, mais il est concevable que ce type de notions se retrouvent dans un sujet de type Maths I. Cette formule du développement en série de la fonction d’erreur pourrait donc être utilisée dans un tel sujet !
On en déduit donc très logiquement un développement limité de la fonction d’erreur. Plus encore, puisque l’on connaît la relation entre la fonction d’erreur et la fonction d’erreur complémentaire, on peut obtenir le développement limité suivant :
\[
\mathrm{erfc}(x) = 1 – \frac{2}{\sqrt{\pi}} \left( x – \frac{x^3}{3} + \cdots + \frac{(-1)^n x^{2n+1}}{(2n+1)\, n!} \right) + o(x^{2n+2})
\]
Applications de la fonction d’erreur
Dans le cadre de la loi normale étudiée en deuxième année, la fonction d’erreur peut être utilisée pour calculer les probabilités associées à des événements dans des systèmes où les variables aléatoires suivent une loi normale. Par exemple, pour une variable aléatoire \( X \sim N(\mu, \sigma^2) \), la probabilité \( P(a \leq X \leq b) \) peut être exprimée en termes de la fonction d’erreur complémentaire et de la fonction de répartition.
La probabilité \( P(a \leq X \leq b) \) est donnée par :
\[
P(a \leq X \leq b) = \Phi\left(\frac{b – \mu}{\sigma}\right) – \Phi\left(\frac{a – \mu}{\sigma}\right)
\]
et en utilisant la fonction d’erreur, cela devient :
\[
P(a \leq X \leq b) = \frac{1}{2} \left[ \text{erf}\left( \frac{b – \mu}{\sigma \sqrt{2}} \right) – \text{erf}\left( \frac{a – \mu}{\sigma \sqrt{2}} \right) \right]
\]
Conclusion
La fonction d’erreur est une fonction intéressante en lien avec l’étude de la loi normale centrée réduite. À ce titre, elle pourrait bien faire partie à l’avenir d’une partie de sujet l’introduisant dans le cadre de l’étude de variables aléatoires sur un sujet de type Maths II.
Tu peux retrouver ici le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux également accéder ici à toutes nos autres ressources mathématiques !