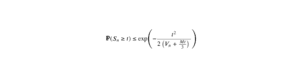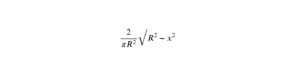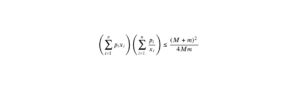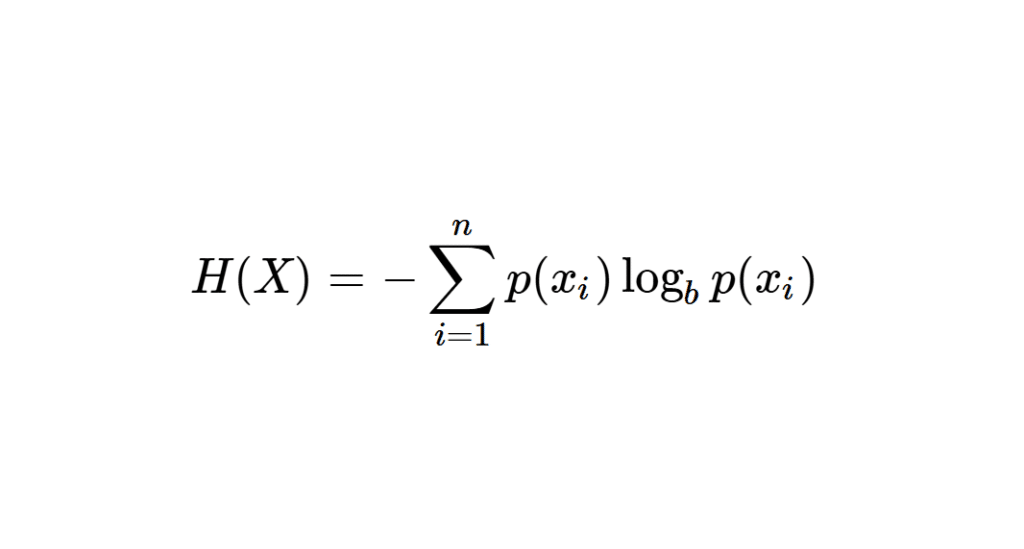
L’entropie de Shannon est une fonction mathématique très classique qui est déjà tombée à de nombreuses reprises, notamment dans des sujets de Maths II. Cette notion a des applications très concrètes, notamment en cryptographie ou en théorie de l’information. Il est donc nécessaire de s’y familiariser afin d’aborder l’épreuve de Maths II de la manière la plus sereine possible.
Introduction
La notion d’entropie de Shannon est déjà apparue plusieurs fois dans les sujets maths appliquées comme approfondies. Dans les maths appliquées, on peut la retrouver notamment dans le Maths II ESSEC 2019 ou 2003. Pour les maths approfondies, on a notamment le Maths I HEC 2012.
En bref, c’est une notion classique que tout bon préparationnaire se doit d’avoir déjà croisée une fois s’il prétend aux Parisiennes !
L’entropie de Shannon a été développée par le mathématicien éponyme dans les années 1950 et permet de déterminer la quantité d’information contenue par une source d’information (les fameux octets). Analysons donc la définition de cette entropie, avant d’étudier ses propriétés et de finir par quelques exemples afin de mieux appréhender la notion.
Définition
De l’entropie
Pour une variable aléatoire discrète \( X \) qui peut prendre \( n \) valeurs différentes \( x_1, x_2, \ldots, x_n \) avec des probabilités respectives \( p(x_1), p(x_2), \ldots, p(x_n) \), l’entropie de Shannon \( H(X) \) est définie par :
\[ H(X) = -\sum_{i=1}^{n} p(x_i) \log_b p(x_i) \]
Où \(\log_b\) désigne le logarithme en base \(b\). En l’espèce, il sera courant d’appliquer cette formule générale au cas \(b = e\) dans la mesure où seul le logarithme de base \(e\) est explicitement au programme d’ECG.
Attention toutefois aux sujets hors programme qui pourraient potentiellement introduire le cas général de la formule. En l’effet, dans son application informatique, il est plutôt courant d’utiliser le logarithme de base \(2\).
De l’entropie conjointe
De la même manière que tu as sûrement défini la loi conjointe dans le cours de deuxième année, il est possible de définir également une entropie conjointe. En voici la définition :
Soient \( X \) et \( Y \) deux variables aléatoires discrètes qui prennent respectivement les valeurs \( x_i \) et \( y_j \) avec des probabilités conjointes \( p(x_i, y_j) \). L’entropie conjointe \( H(X, Y) \) est définie par :
\[ H(X, Y) = -\sum_{i} \sum_{j} p(x_i, y_j) \log_b p(x_i, y_j) \]
Tu peux noter que si \( X \) et \( Y \) sont indépendantes, alors \( p(x_i, y_j) = p(x_i)p(y_j) \), et l’entropie conjointe est simplement la somme des entropies individuelles : \( H(X, Y) = H(X) + H(Y) \).
De l’entropie conditionnelle
Dernière définition relative à l’entropie : l’entropie conditionnelle (et, encore une fois, tu peux faire le lien avec les lois conditionnelles vues dans le cours de maths de deuxième année).
En voici une définition en utilisant les mêmes notations que précédemment :
\[ H(X|Y) = -\sum_{y \in Y} p(y) \sum_{x \in X} p(x|y) \log_b p(x|y) \]
Propriétés
Positivité
Puisque \( 0 \leq p(x_i) \leq 1 \), nous avons \( \log_b p(x_i) \leq 0 \). Ainsi, \( -p(x_i) \log_b p(x_i) \geq 0 \) pour chaque \( i \). En sommant ces termes qui sont tous positifs, nous obtenons :
\[
H(X) \geq 0
\]
Maximalité
L’entropie est maximale lorsque toutes les valeurs possibles de \( X \) sont équiprobables, c’est-à-dire dans le cas d’une loi uniforme.
Pour une distribution uniforme où \( p(x_i) = \frac{1}{n} \) pour tout \( i \), l’entropie est :
\[
H(X) = -\sum_{i=1}^{n} \frac{1}{n} \log_b \frac{1}{n} = \log_b n
\]
Pour montrer que c’est un maximum, on utiliserait l’inégalité de Jensen pour la fonction concave \( \log_b \). Voici cette rapide démonstration :
\[
\sum_{i=1}^{n} p_i \log_b \frac{1}{p_i} \leq \log_b \left( \sum_{i=1}^{n} p_i \cdot \frac{1}{p_i} \right) = \log_b n\]
Il faudrait encore montrer que ce maximum est unique, mais cela n’est pas vraiment le sujet de cet article (indice : utilisation des fonctions à n-variables).
À supposer que l’on a démontré cela, on parvient bien à la conclusion souhaitée.
Additivité
Pour deux variables aléatoires indépendantes \( X \) et \( Y \), l’entropie conjointe est la somme des entropies individuelles : \( H(X, Y) = H(X) + H(Y) \). Nous l’avions déjà mentionné avant sans donner le nom de cette propriété !
Si \( X \) et \( Y \) sont indépendants, \( p(x_i, y_j) = p(x_i)p(y_j) \).
L’entropie conjointe est alors :
\[ H(X, Y) = -\sum_{i,j} p(x_i, y_j) \log_b p(x_i, y_j) \]
\[ = -\sum_{i,j} p(x_i)p(y_j) \log_b (p(x_i)p(y_j)) \]
\[ = -\sum_{i,j} p(x_i)p(y_j) (\log_b p(x_i) + \log_b p(y_j)) \]
\[ = H(X) + H(Y) \]
Propriété de la chaîne
Pour deux variables aléatoires \( X \) et \( Y \), l’entropie conjointe peut être décomposée comme suit :
\[
H(X, Y) = H(X) + H(Y|X)
\]
Démonstration :
\[
H(X, Y) = -\sum_{i,j} p(x_i, y_j) \log_b p(x_i, y_j)
\]
En utilisant \( p(x_i, y_j) = p(x_i) p(y_j|x_i) \), nous obtenons :
\[
H(X, Y) = -\sum_{i,j} p(x_i, y_j) \log_b (p(x_i) p(y_j|x_i))
\]
Ce qui se sépare en (indice : propriétés du logarithme, système complet d’évènements et linéarité de la somme) :
\[
H(X, Y) = -\sum_{i} p(x_i) \log_b p(x_i) – \sum_{i,j} p(x_i, y_j) \log_b p(y_j|x_i) = H(X) + H(Y|X)
\]
Exemples
Entropie d’une variable de Bernoulli (facile)
Question
Soit \( X \) une variable aléatoire de Bernoulli qui prend la valeur 1 avec une probabilité \( p \). Calculer l’entropie de Shannon \( H(X) \).
Réponse
L’entropie de Shannon pour une variable de Bernoulli est donnée par :
\[ H(X) = – [p \log_2 p + (1-p) \log_2 (1-p)] \] (application directe de la formule)
Entropie conditionnelle avec logarithme naturel (moyen)
Question
Soit \( X \) et \( Y \) deux variables aléatoires discrètes avec la distribution conjointe suivante :
\[
\begin{array}{c|cc}
X / Y & y_1 & y_2 \\
\hline
x_1 & 0.4 & 0.2 \\
x_2 & 0.1 & 0.3 \\
\end{array}
\]
Calculer l’entropie conditionnelle \( H(X|Y) \) en utilisant le logarithme naturel.
Réponse
Il s’agit tout d’abord de déterminer les probabilités marginales \( p(y) \) (rappelle-toi de la formule de calcul de l’entropie conditionnelle).
\[ p(y_1) = 0.5 \]
\[ p(y_2) = 0.5 \]
Déterminons ensuite les probabilités conditionnelles \( p(x|y) \) :
\[ p(x_1|y_1) = 0.8 \]
\[ p(x_2|y_1) = 0.2 \]
\[ p(x_1|y_2) = 0.4 \]
\[ p(x_2|y_2) = 0.6 \]
Par application de la formule, il vient :
\[ H(X|Y) = – \left[ 0.5 \left( 0.8 \ln 0.8 + 0.2 \ln 0.2 \right) + 0.5 \left( 0.4 \ln 0.4 + 0.6 \ln 0.6 \right) \right] \]
En calculant les valeurs, on obtient :
\[ H(X|Y) \approx 0.825 \]
Conclusion
On a fait le tour de tout ce qu’il y a à savoir autour de la notion d’entropie de Shannon. Si tu souhaites t’entraîner davantage (ce que je ne peux que te recommander vivement), voici le sujet S17 des oraux HEC 2022.
Tu peux retrouver le méga-répertoire qui contient toutes les annales de concours et les corrigés. Tu peux également accéder à toutes nos autres ressources mathématiques !